AWS Trainium News 2026: Project Rainier, the $100B Anthropic Deal, and the Enterprise Case Against Nvidia

The Brief
The Pulse AWS operates the world’s largest AI compute cluster not built on Nvidia chips. Project Rainier, activated in October 2025 across a 1,200-acre facility in Indiana, connects more than 500,000 Trainium2 chips into a single cluster providing five times the compute power Anthropic used to train previous Claude generations. Every inference request to Anthropic’s […]
Why It Matters
The story matters because it changes how buyers, builders, or policymakers should read the AI Infrastructure market.
Watch Next
Watch whether the signal becomes a budget, procurement, or platform decision in the next cycle.
The Pulse
AWS operates the world’s largest AI compute cluster not built on Nvidia chips. Project Rainier, activated in October 2025 across a 1,200-acre facility in Indiana, connects more than 500,000 Trainium2 chips into a single cluster providing five times the compute power Anthropic used to train previous Claude generations. Every inference request to Anthropic’s Claude models on Amazon Bedrock today runs on Trainium architecture. In December 2025, AWS launched Trainium3 at re:Invent, its first chip on TSMC’s 3nm process, delivering 4.4 times the compute performance of Trainium2 at 50% lower cost than comparable Nvidia GPU instances.
In April 2026, Anthropic committed more than $100 billion to AWS technologies over ten years and secured up to 5 gigawatts of Trainium capacity.
The Trainium news in 2026 is the story of AWS silicon moving from an interesting Nvidia alternative into infrastructure powering the most commercially significant frontier AI deployment in the world. For enterprise AI teams evaluating whether to use Trainium or continue with Nvidia instances on AWS, the cost economics and Bedrock integration evidence have never been stronger.
Core significance
Why it matters:
- Trainium is now powering the majority of Amazon Bedrock inference: AWS CEO Matt Garman confirmed that the majority of Amazon Bedrock inference workloads now run on Trainium architecture, and that for Anthropic’s latest Claude models in Bedrock, all traffic runs on Trainium delivering the best response times of any major provider. This is a production deployment fact, not a benchmark claim. The cluster provides five times the compute power Anthropic used to train its previous model generation.[About Amazon — Trainium3 UltraServers official announcement December 2025]
- Anthropic’s $100 billion AWS commitment is the largest enterprise AI infrastructure deal in history: On April 20, 2026, Anthropic committed more than $100 billion to AWS technologies over ten years, securing up to 5 gigawatts of Trainium capacity covering Trainium2, Trainium3, and Trainium4. Nearly 1 gigawatt of combined Trainium2 and Trainium3 capacity is expected online by end of 2026. The remaining 4 gigawatts arrives across 2027 to 2029 as Trainium3 and Trainium4 production scales.[Anthropic official — Anthropic Amazon expanded collaboration 5GW Trainium]
- 50% cost reduction versus comparable Nvidia GPU instances is validated by named customers: AWS confirmed that organisations can save up to 50% on training and inference costs compared to GPU-based instances. Decart, specialising in generative AI video models, reported four times faster frame generation at half the cost of GPU instances using Trainium3. Early customers include Anthropic, Karakuri, Metagenomi, NetoAI, Ricoh, and Splash Music.[Data Centre Magazine — Trainium3 50% cost reduction enterprise customers confirmed]
Deep Context: How AWS built the World’s Largest Non-Nvidia AI cluster
AWS entered custom AI silicon in 2015 with the acquisition of Annapurna Labs for $350 million. The acquisition has become one of the most strategically important technology deals of the decade. Annapurna’s team has since produced Graviton for general compute, Inferentia for AI inference, and the Trainium family for AI training, all now critical to AWS’s competitive position against Microsoft Azure and Google Cloud.
The Trainium family has moved through three generations in five years. Trainium1, unveiled at re:Invent 2020 and available in EC2 Trn1 instances by 2022, was built on 7nm and established the Neuron SDK toolchain. Trainium2, on 5nm with a new NeuronCore-v3 architecture, quadrupled the compute core count and delivered 30 to 40% better price-performance than Nvidia H100 instances. Trainium3, announced at re:Invent 2025 and reaching general availability in December 2025, is the step change: TSMC’s 3nm process and 4.4 times the compute performance of Trainium2 UltraServers.[Data Center Knowledge — AWS launches Trainium3 to challenge Nvidia re:Invent 2025]
Project Rainier is the proof of concept at scale. AWS and Anthropic designed the cluster to train frontier models, connecting more than 500,000 Trainium2 chips through custom NeuronLink interconnect across the Indiana facility. The fact that Anthropic chose Trainium over Nvidia for its primary training infrastructure is the most credible independent validation of AWS silicon’s frontier capability.
As covered in our AI data center power consumption analysis, energy efficiency has become as important as raw performance as data center power constraints tighten. Trainium3’s 4x improvement in energy efficiency over Trainium2 is not just a cost saving. It is a power budget advantage in facilities where total facility power gates cluster size.
Data insights
By the numbers:
Trainium3 specifications from AWS official product page primary source. Performance comparisons from Introl February 2026 guide cross-verified against AWS and Data Centre Magazine primary sources.
- 2.52 petaflops FP8 + 144 GB HBM3e + 4.9 TB/s bandwidth: Trainium3 per-chip specifications confirmed on the AWS official Trainium product page. A single Trn3 UltraServer with 144 chips delivers 362 FP8 petaflops, 20.7 TB total HBM3e, and 706 TB/s aggregate memory bandwidth. The 4.9 TB/s per-chip bandwidth is 70% more than Trainium2.[AWS official — Trainium product page full specifications]
- 4.4x compute + 4x energy efficiency + 4x memory bandwidth: Trainium3 UltraServer improvements versus Trainium2 UltraServers across all three performance dimensions. The 4x energy efficiency gain is particularly significant as power constraints increasingly limit cluster scale: a 40% reduction in power consumption per unit of compute allows larger clusters within the same facility power budget.[Introl — AWS Trainium Inferentia silicon ecosystem guide 2026]
- 50% cost savings on enterprise workloads: Enterprise teams reducing training and inference costs by up to 50% versus comparable GPU instances, validated across multiple early customers. Trainium2 instances cost roughly half the price of comparable H100 instances for many workloads, with Trainium3 maintaining that cost advantage at materially higher performance.[Technology Magazine — Trainium3 cost savings enterprise validation]
- 100,000+ customers on Amazon Bedrock running Claude: Both Trainium and Graviton are each used by more than 100,000 customers. Over 100,000 customers run Anthropic Claude models on Amazon Bedrock, making Claude one of the most popular model families on the platform. The April 2026 announcement also integrates the full Anthropic-native Claude console directly into AWS, requiring no separate contract or billing relationship.[About Amazon — Amazon Anthropic April 2026 $5B additional investment]
- 500,000+ Trainium2 chips in Project Rainier, 1 million+ total deployed: Project Rainier houses nearly 500,000 Trainium2 chips, activated in late 2025. By April 2026, Anthropic confirmed it currently uses over one million Trainium2 chips to train and serve Claude. The additional 5GW commitment extends this infrastructure pipeline across Trainium2, Trainium3, and Trainium4 through 2029.[Nerd Level Tech — Amazon Anthropic $100B deal 5GW compute full breakdown]
Table 1: AWS Trainium generation comparison: Trn1 to Trn4
| Generation | Process node | FP8 compute per chip | Key improvement | Enterprise availability |
| Trainium1 (2020) | 7nm | Baseline (FP32/BF16) | First AWS training accelerator; established Neuron SDK | EC2 Trn1 from 2022 |
| Trainium2 (2023) | 5nm | ~0.6 petaflops | 4x compute cores; 30-40% better price-perf vs H100 | EC2 Trn2; UltraServer; Project Rainier |
| Trainium3 (Dec 2025) | 3nm (TSMC) | 2.52 petaflops FP8 | 4.4x vs Trn2; 4x efficiency; 50% cost vs Nvidia GPU | EC2 Trn3 UltraServer GA |
| Trainium4 (roadmap) | Next-gen | 6x FP4 vs Trn3; 3x FP8 | NVLink Fusion — hybrid GPU/Trainium clusters | Announced at re:Invent 2025 |
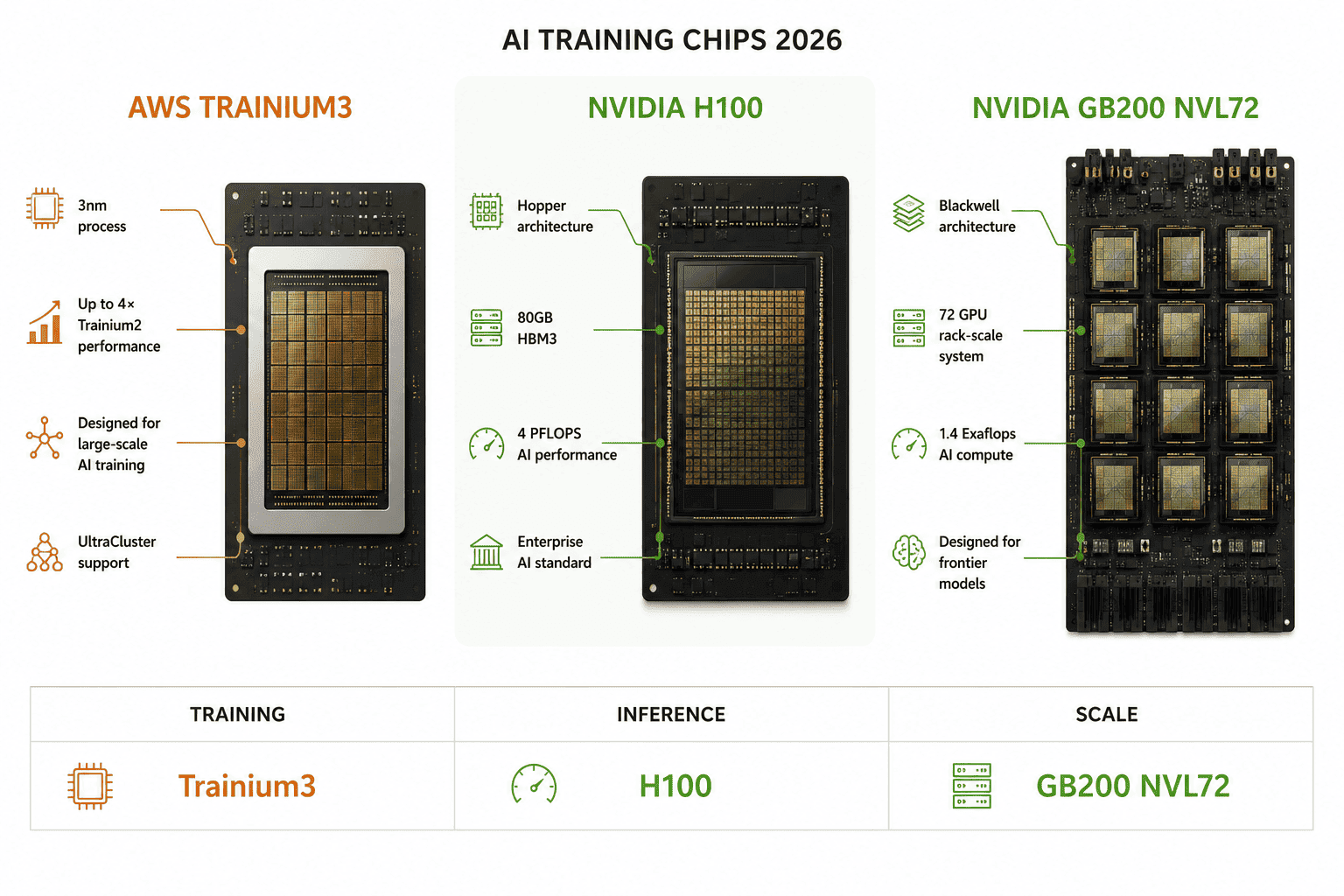
Table 2: Trainium3 vs Nvidia H100 vs GB200: Enterprise comparison
| Dimension | Trainium3 UltraServer | Nvidia H100 SXM5 | Nvidia GB200 NVL72 |
| Chip count per server | 144 chips | 8 GPUs | 72 GPUs |
| FP8 compute total | 362 PFLOPs | ~32 PFLOPs (8x H100) | ~720 PFLOPs |
| Memory total | 20.7 TB HBM3e | 3.2 TB HBM3 | 13.5 TB HBM3e |
| Cost vs comparable | 50% lower than GPU instances | Baseline | 30-40% premium over H100 |
| Cooling | Liquid mandatory | Air and liquid | Liquid mandatory |
| Software ecosystem | Neuron SDK; PyTorch native; HuggingFace; vLLM | CUDA; broadly supported | CUDA; broadly supported |
| Best for | Cost-optimised workloads on AWS Bedrock | Broad compatibility; existing CUDA code | Frontier model training; max compute density |
The Enterprise Case: when to use Trainium instead of Nvidia
The honest enterprise evaluation of Trainium versus Nvidia GPU instances on AWS comes down to three questions: what workloads you are running, how much engineering investment you can make in the Neuron SDK, and whether you are running primarily on AWS.
When Trainium makes financial sense
Trainium3 delivers its 50% cost advantage most clearly on workloads already running on Trainium2 and on new workloads started on Trainium from scratch. The Neuron SDK now supports native PyTorch with a one-line change to switch from CUDA. vLLM, HuggingFace, TorchTitan, TRL, Ray, Slurm, and Amazon EKS are all supported. Enterprises running large-scale inference on Amazon Bedrock are already running on Trainium whether they know it or not. The strongest Trainium case is for organisations with significant Bedrock usage considering running fine-tuned models, where consistent Trainium architecture across training and inference eliminates translation overhead.
When Nvidia remains the better choice
Nvidia holds approximately 90% market share in AI accelerators, driven by the CUDA ecosystem’s depth rather than price alone. Virtually every AI framework, library, and tool has been built and optimised for CUDA first. Organisations with existing CUDA-optimised codebases, researchers needing access to the latest academic model architectures before Neuron optimisation, and enterprises on Azure or Google Cloud rather than AWS should not default to Trainium.
The Trainium4 NVLink Fusion announcement changes this calculus. Trainium4 will work in hybrid clusters alongside Nvidia GPUs, enabling enterprises to use Trainium4 for cost-sensitive workloads while keeping Nvidia GPUs for CUDA-dependent workloads without rebuilding their entire AI infrastructure. That is the architecture that closes the remaining gap between Trainium’s cost economics and Nvidia’s ecosystem depth.
Expert nuance: the Neuron SDK gap is narrowing but real
The primary engineering objection to Trainium adoption is the Neuron SDK learning curve. CUDA has been the default AI accelerator programming environment since 2007 and virtually every AI framework assumes CUDA availability. The Neuron SDK, while significantly more mature in 2026 than in 2022, still requires workload-specific validation and occasional kernel-level optimisation for workloads developed exclusively on CUDA.
The SemiAnalysis deep dive on Trainium3 published in December 2025 confirms that the Trainium3 NL72x2 Switched architecture is genuinely comparable to Nvidia’s GB200 NVL72 in its all-to-all scale-up topology. The NeuronSwitch delivers twice the bandwidth within each UltraServer compared to Trainium2. AWS has also integrated CPU directly into compute trays in the NL72x2 Switched configuration, mirroring Nvidia’s Grace-Vera approach. [SemiAnalysis — AWS Trainium3 deep dive NL72x2 architecture December 2025]
The honest enterprise assessment is that the Neuron SDK investment required to run on Trainium is a one-time cost that pays back quickly at the 50% cost reduction level. An organisation running $2 million per year in GPU instance costs that achieves a 40% reduction after Neuron optimisation recovers the engineering investment in months, not years.
Strategic outlook
- Trainium4 and NVLink Fusion change the hybrid compute calculus: The announcement that Trainium4 will support Nvidia NVLink Fusion enables Trainium4 chips to operate in the same cluster as Nvidia GPUs, sharing the high-speed interconnect. Enterprises running mixed AI workloads can use Trainium4 for cost-sensitive jobs while keeping Nvidia for CUDA-dependent workloads. The either-or framing of Trainium versus Nvidia becomes a both-and architectural choice. AWS is actively developing Trainium4 with at least 6x FP4 throughput, 3x FP8 performance, and 4x more memory bandwidth versus Trainium3. [Uncover Alpha — Trainium family history Trainium4 NVLink roadmap]
- The Anthropic deal validates Trainium for enterprises that need governance credibility: Anthropic is one of the most rigorous AI safety organisations in the industry. Its choice to run all Claude production inference on Trainium, and its $100 billion commitment to AWS, validates that Trainium meets the technical and security standards of frontier AI development. For regulated enterprise AI deployments in healthcare, financial services, and government, the Anthropic proof of concept provides a credible governance reference.
- The 1 million chip deployment threshold signals enterprise operational readiness: AWS confirmed Trainium is now deployed at over 1 million chips in production across Project Rainier and Bedrock infrastructure. This scale means operational reliability, failure modes, and support processes for Trainium are known at a depth unavailable when early enterprise customers evaluated the technology in 2022 and 2023. Enterprises evaluating Trainium in 2026 are evaluating a chip with 1 million-chip production proof at the world’s largest commercial AI inference platform.
Key question answered
What is the latest AWS Trainium news in 2026?
The most significant Trainium news in 2026 covers three events. Trainium3 reached general availability in December 2025 at re:Invent, delivering 2.52 petaflops FP8 per chip on TSMC 3nm, 4.4 times the performance of Trainium2 UltraServers, 4 times greater energy efficiency, and 50% lower cost than comparable Nvidia GPU instances. A single Trn3 UltraServer hosts 144 chips for 362 total FP8 petaflops and 20.7 TB HBM3e. Project Rainier, activated October 2025, houses 500,000-plus Trainium2 chips across a 1,200-acre Indiana facility and is now the world’s largest non-Nvidia AI cluster. The majority of Amazon Bedrock inference runs on Trainium. On April 20, 2026, Anthropic committed more than $100 billion to AWS over ten years securing up to 5 gigawatts of Trainium capacity. Nearly 1 gigawatt arrives by end of 2026. Trainium4 is announced with 6 times FP4 throughput versus Trainium3 and Nvidia NVLink Fusion support for hybrid GPU/Trainium deployments.
The Takeaway
AWS Trainium has crossed a threshold in 2026 that custom silicon alternatives to Nvidia have been trying to reach for a decade. It is not a theoretical cost-saving option for experimental AI teams. It is the production infrastructure running the most commercially deployed frontier AI model in the world. When every Claude query on Amazon Bedrock runs on Trainium, and Anthropic commits $100 billion to keeping it that way, Trainium’s production readiness is no longer a hypothesis.
The 50% cost advantage versus Nvidia GPU instances is real and documented by multiple enterprise customers. The Neuron SDK investment required to capture that advantage is also real and should be evaluated honestly. The enterprises that will see the strongest returns are those primarily on AWS, running significant Bedrock workloads, and willing to invest 60 to 90 days of engineering time in Neuron SDK integration for their highest-cost training and inference workloads.
The Trainium4 NVLink Fusion announcement is the signal that matters most for infrastructure planning beyond 2026. If Trainium4 delivers hybrid cluster capability with Nvidia GPUs, migration to Trainium becomes a financial optimisation decision rather than an architectural commitment. Enterprises can move cost-sensitive workloads to Trainium while keeping CUDA-dependent workloads on Nvidia. That is the architecture that closes the remaining gap between Trainium’s cost economics and Nvidia’s ecosystem depth.